Revolusi AI Desktop: Peran CPU Arm dalam Sistem RAG Lokal
Menurut artikel karya Odin Shen: Rethinking the Role of CPUs in AI: A Practical RAG Implementation on DGX Spark
Target Audiens: Tim IT/R&D, system integrator, serta tim teknis yang perlu mengimplementasikan RAG di dalam intranet perusahaan.
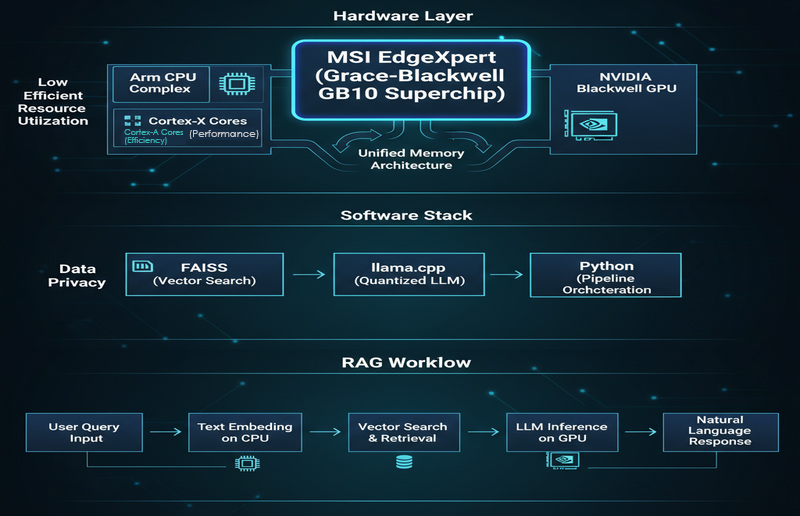
Konteks Platform: MSI EdgeXpert (Platform NVIDIA GB10 / DGX Spark).
Kata kunci: EdgeXpert, Local RAG, CPU embedding, Unified Memory, Low-latency inference, FAISS, llama.cpp.
Ringkasan 30 Detik (TL;DR)
- Keunggulan CPU dalam Proses Embedding: Pada tahap embedding dalam sistem RAG lokal, permintaan berskala kecil dengan latensi rendah lebih efektif ditangani oleh CPU. Proses embedding memiliki latensi sekitar 70–90 ms, yang sudah memadai untuk mendukung kueri interaktif..
- Keunggulan Unified Memory: Unified memory secara signifikan menekan biaya perpindahan data dari CPU ke GPU. Hampir tidak diperlukan proses penyalinan data yang besar saat beralih dari proses embedding di CPU ke tahap generasi di GPU.
- Evidence-Based AI: Nilai terbesar dari RAG bukan sekadar “menulis dengan lebih baik”, melainkan menghasilkan jawaban yang berlandaskan data. Respons dapat merujuk langsung ke bab atau tabel dokumen tertentu, sehingga mengurangi risiko halusinasi AI.
- Siap untuk diimplentasi Platform AI kelas desktop kini siap untuk langsung digunakan. Solusi lengkap yang mencakup vector retrieval (FAISS) dan inferensi lokal dapat dijalankan dalam satu platform edge desktop.
Latar Belakang Masalah: Mengapa Pencarian Data Internal Menjadi Bottleneck?
Dalam lingkungan perusahaan, data seperti spesifikasi, manual proyek, dan catatan operasional sering tersebar di berbagai sistem atau file server. Pencarian berbasis kata kunci konvensional kerap tidak efektif karena adanya sinonim, singkatan, dan perbedaan versi dokumen. Di sisi lain, mengunggah data internal ke LLM berbasis cloud sering kali tidak memungkinkan karena pertimbangan keamanan dan kepatuhan. Oleh karena itu, penerapan sistem Local RAG (Retrieval-Augmented Generation) yang berjalan sepenuhnya offline atau di dalam intranet menjadi solusi yang diinginkan oleh banyak tim.
Arsitektur Minimum Viable Local RAG (Dapat Direplikasi)
Berikut adalah alur kerja RAG umum yang cocok untuk platform desktop/edge dan dapat diimplementasikan dengan cepat:
- Pengumpulan & Pembersihan Dokumen: Ekspor dokumen PDF/Word/Markdown/halaman web, samakan encoding, lalu lakukan segmentasi paragraf (chunking)
- Embedding: Mengonversi setiap chunk menjadi vektor.
- Vector Database: Menggunakan FAISS untuk membangun indeks dan menyimpan vektor.
- Query: Melakukan embedding pada pertanyaan pengguna untuk menemukan fragmen dokumen yang paling relevan (Top-K).
- Generation: Mengirim fragmen bukti yang telah diambil bersama pertanyaan ke LLM lokal (misalnya llama.cpp) untuk menghasilkan jawaban, sambil menyertakan rujukan paragraf atau bab.
Data Observasi Kunci
Metrik
Observasi (Implementasi Ini)
Latensi Embedding
Sekitar 70–90 ms (interaktif, latensi rendah).
Penggunaan DRAM (Idle → Puncak RAG)
DRAM Usage (Idle → RAG Peak) Approx. 3.5 GB → Approx. 14 GB (Increased by approx. 10 GB)
CPU Embedding → GPU Generation Switch
Penggunaan DRAM (Idle → Puncak RAG): Sekitar 3,5 GB → 14 GB (bertambah sekitar 10 GB).
Contoh Software Stack
FAISS (Retrieval) + llama.cpp (Inference)
Surprise 1: CPU Jadi Bintang — Lebih Cepat dari GPU untuk Embedding RAG
Banyak orang secara intuitif mengira bahwa AI sepenuhnya bergantung pada GPU. Namun, embedding dalam RAG sering kali berupa beban kerja dengan kalimat pendek, batch kecil, dan kebutuhan respons real-time. Pada kondisi seperti ini, memindahkan proses ke GPU justru dapat menimbulkan overhead tambahan, mulai dari latensi penjadwalan, transfer data melalui PCIe/bus, hingga pemanfaatan sumber daya GPU yang tidak optimal.
Pada platform seperti MSI EdgeXpert (DGX Spark), CPU Arm sangat unggul dalam menangani beban kerja dengan latensi rendah, alur pemrosesan yang bercabang tinggi, dan kebutuhan komputasi yang fleksibel, seperti:
- Proses Komputasi Lebih Cepat: Menghilangkan proses inisialisasi/penjadwalan GPU serta perpindahan data yang biasanya dibutuhkan.
- Lebih Cocok untuk Batch Kecil: Embedding untuk kueri singkat umumnya tidak mampu memanfaatkan GPU secara penuh.
- Pengalaman Interaksi yang Lebih Stabil: Dengan waktu embedding sekitar 70–90 ms, total latensi dari proses “Query → Retrieval → Jawaban” tetap berada dalam rentang yang nyaman dan dapat diterima oleh pengguna.
Kesimpulan: CPU kini bukan lagi sekadar pre-processor, melainkan berperan sebagai mesin latensi rendah yang mampu meningkatkan kecepatan respons inferensi pada platform desktop.
Surprise 2: Highway Bersama CPU & GPU — Cara Unified Memory Mempercepat Aliran Data
Arsitektur tradisional sering mirip dengan perlombaan estafet: CPU menyelesaikan perhitungan dan harus “menyalin” data ke GPU (melalui bus PCIe), yang menimbulkan waktu tambahan dan tekanan pada memori. Konsep Unified Memory ibarat lintasan bersama: CPU dan GPU dapat mengakses data yang sama secara langsung, sehingga biaya perpindahan data berkurang.
Perilaku memori yang diamati pada implementasi ini mendukung hipotesis ini:
- Kontrol Memori yang Efisien: Penggunaan memori saat idle sekitar 3,5 GB, meningkat hingga sekitar 14 GB saat RAG, dengan kenaikan total sekitar 10 GB, menunjukkan pemanfaatan sumber daya yang tinggi.
- Peralihan Embedding → Generation Hampir Tidak Menimbulkan Peningkatan Memori: Peralihan dari embedding di CPU (±13 GB) ke generasi di GPU (±14 GB) hanya menunjukkan peningkatan kecil, sesuai dengan karakteristik “tanpa penyalinan data besar-besaran.”
Kesimpulan: Unified memory menjadi fondasi penting untuk mencapai RAG dengan latensi rendah pada platform desktop/edge.
Surprise 3: Menangkal Halusinasi AI di Lokal — Jawaban Berbasis Bukti
Salah satu risiko terbesar di bidang teknis adalah terlalu percaya diri tapi salah. Saat sebuah model kurang memiliki pengetahuan domain spesifik atau dokumen yang digunakan sudah usang, halusinasi bisa terjadi. RAG mengaitkan jawaban dengan dasar dokumen melalui prinsip “ambil bukti dulu, baru hasilkan jawaban.”
Kami melakukan uji kontrol menggunakan pertanyaan seputar pin GPIO Raspberry Pi, dan hasilnya cukup intuitif:
- Tanpa RAG: Pertanyaan yang sama diajukan pada waktu berbeda menghasilkan jawaban yang kontradiktif dan salah, meski nada penyampaiannya tetap terdengar yakin.
- Dengan RAG: Jawaban yang dihasilkan konsisten dengan dokumentasi resmi dan dapat merujuk langsung ke bab atau tabel tertentu (misalnya, nomor tabel spesifik).
Conclusion: Nilai utama RAG terletak pada kemampuannya untuk “ditelusuri dan diverifikasi”, mengubah jawaban menjadi output teknis yang berbasis sumber.
Surprise 4: AI Desktop Bukan Lagi Eksperimen — Platform yang Siap Digunakan
Platform AI kelas desktop telah berkembang dari sekadar showpiece menjadi lingkungan pengembangan yang siap digunakan. Mengambil MSI EdgeXpert (platform DGX Spark) sebagai contoh, platform ini tidak hanya menyediakan kekuatan komputasi, tetapi juga desain termal dan akustik yang memungkinkan perangkat berjalan lama di atas meja kantor, sambil mendukung software stack lengkap mulai dari vector retrieval hingga inferensi lokal.
Deployment Value:
- Data Tetap di Dalam Intranet: Mendukung privasi data perusahaan dan kepatuhan regulasi.
- Konstruksi Cepat: FAISS + llama.cpp membentuk stack minimal yang dapat langsung digunakan.
- Skalabilitas: Penambahan selanjutnya dapat mencakup kontrol akses, log audit, manajemen versi dokumen, dan pencarian multi-bahasa.
Pendekatan yang Disarankan: Mengubah Artikel Ini Menjadi Checklist PoC yang Bisa Dieksekusi
Jika Anda ingin memvalidasi Local RAG dengan cepat di dalam intranet perusahaan, disarankan untuk mengikuti urutan langkah berikut:
- Tentukan Pertanyaan: Pertama, tentukan 3–5 pertanyaan yang sering digunakan dan memiliki jawaban jelas (misalnya, spesifikasi papan tertentu, parameter BIOS, atau SOP proses).
- Siapkan Dokumen: Siapkan 50–200 dokumen representatif, pastikan versi dokumen benar dan dapat diparsing..
- Chunking & Indexing:Mulai dengan segmentasi konservatif (misalnya, 300–800 token per segmen, dengan overlap) dan buat indeks FAISS.
- Evaluasi Latensi & Tingkat Kecocokan (Hit Rate): Ukur latensi embedding, kualitas Top-K retrieval, dan waktu respons keseluruhan.
- Tambahkan Output Rujukan:Pastikan jawaban menyertakan paragraf atau bab sumber, agar tidak terkesan meyakinkan tanpa sumber yang dapat diverifikasi.
- Peluncuran Bertahap: Tambahkan Access Control List (ACL), log, dan proses pembaruan dokumen sebelum memperluas cakupan data.
FAQ
Q1: Mengapa embedding lebih cepat saat dijalankan di CPU?
A: Karena query biasanya berupa batch kecil dan kalimat pendek. CPU menghindari proses penjadwalan dan perpindahan data GPU, sehingga mengurangi latensi keseluruhan..
A: Karena query biasanya berupa batch kecil dan kalimat pendek. CPU menghindari proses penjadwalan dan perpindahan data GPU, sehingga mengurangi latensi keseluruhan..
Q2: Apa manfaat Unified Memory untuk RAG?
A: Ini mengurangi kebutuhan penyalinan data besar-besaran dari CPU ke GPU, sehingga tahap retrieval vektor dapat terhubung langsung dengan tahap generasi, meningkatkan kecepatan respons dan efisiensi pemanfaatan sumber daya.
A: Ini mengurangi kebutuhan penyalinan data besar-besaran dari CPU ke GPU, sehingga tahap retrieval vektor dapat terhubung langsung dengan tahap generasi, meningkatkan kecepatan respons dan efisiensi pemanfaatan sumber daya.
Q3:Apakah Local RAG memerlukan GPU?
A: Tidak selalu. Tahap retrieval dan embedding dapat diselesaikan dengan efisien oleh CPU; namun, jika tahap generasi menggunakan model yang lebih besar atau membutuhkan throughput tinggi, GPU tetap memberikan keuntungan signifikan.
A: Tidak selalu. Tahap retrieval dan embedding dapat diselesaikan dengan efisien oleh CPU; namun, jika tahap generasi menggunakan model yang lebih besar atau membutuhkan throughput tinggi, GPU tetap memberikan keuntungan signifikan.
Q4: Bagaimana cara mengurangi halusinasi AI?
A:Dengan mengaitkan jawaban pada dasar dokumen dan memastikan output menyertakan paragraf/bab sumber, sekaligus membatasi model agar tidak “mengarang fakta” yang tidak ada di dokumen."
A:Dengan mengaitkan jawaban pada dasar dokumen dan memastikan output menyertakan paragraf/bab sumber, sekaligus membatasi model agar tidak “mengarang fakta” yang tidak ada di dokumen."
Ringkasan: Menempatkan Ulang Peran CPU dalam Arsitektur AI Desktop
Pengalaman mengimplementasikan Local RAG di MSI EdgeXpert (Platform GB10/DGX Spark) menunjukkan bahwa AI Desktop bukan lagi sekadar versi mini dari data center, melainkan jalur yang nyata dan siap digunakan. Dalam konteks ini, CPU bukan peran pasif, melainkan komponen inti dalam arsitektur kolaboratif yang mempengaruhi latensi dan pengalaman pengguna.